Ollama
-
Qué es Open Knowledge Format (OKF) y qué arregla de tu RAG
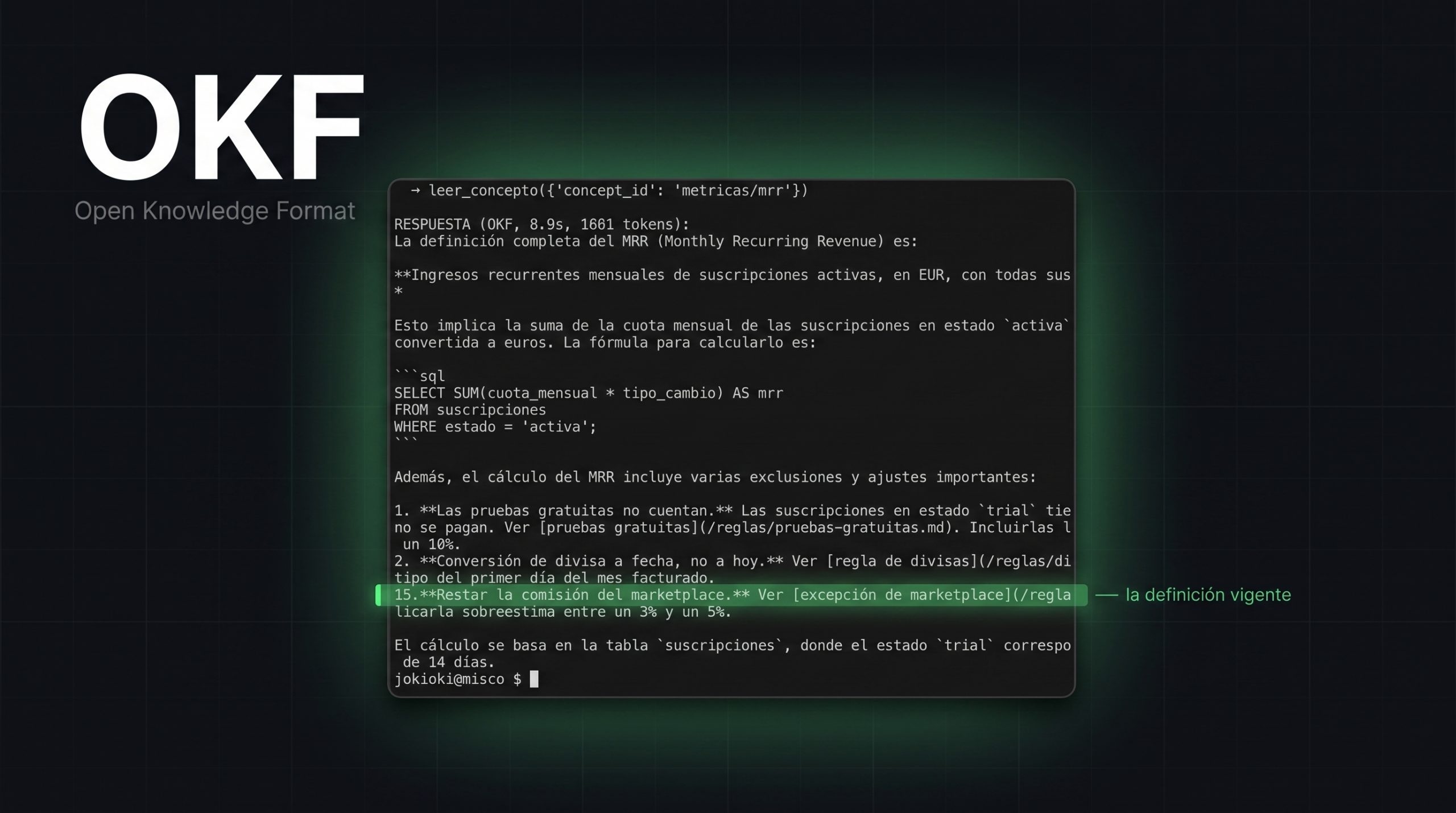
Le hice a mi RAG una pregunta que se hace en cualquier empresa cien veces al mes: ¿cómo calculamos los ingresos? Me respondió con una definición obsoleta desde hacía tres meses. Con IVA incluido y contando los pedidos cancelados, cuando la definición vigente es justo lo contrario. Un error del 20% en periodos con muchas…
-
IA local en WordPress 7: cómo conectar Ollama sin API key

Desde WordPress 7 puedes conectar tu web a un modelo de inteligencia artificial que corre en tu propio ordenador, gratis y sin ninguna clave de API. No necesitas OpenAI, no pagas por token y el contenido de tu web no sale de tu red. En esta guía te explico cómo hacerlo con Ollama y un…
-
SpecJudge: cómo elegir el modelo de IA con mejor relación calidad/precio para tu proyecto

Cuando terminas de definir un proyecto y llega el momento de implementarlo con IA, aparece una pregunta que cuesta dinero responder mal: ¿qué modelo elijo? Si tiro de uno muy potente para una tarea sencilla, estoy pagando por una capacidad que el proyecto no va a usar. Y si elijo uno demasiado justo para algo…
-
Cuantización de modelos de IA: la guía técnica para correr LLMs en tu propio PC

Por Joaquín Ruiz — autor, divulgador y experto en IA · Zaragoza Un modelo como Llama 3.1 70B ocupa, en su forma nativa, alrededor de 140 gigabytes de memoria. Eso es hardware de datacenter: imposible ejecutarlo en un ordenador normal. Y, sin embargo, miles de desarrolladores lo están corriendo ahora mismo en sus propias máquinas,…
Search
Recent Posts
- Qué es Open Knowledge Format (OKF) y qué arregla de tu RAG
- IA local en WordPress 7: cómo conectar Ollama sin API key
- SpecJudge: cómo elegir el modelo de IA con mejor relación calidad/precio para tu proyecto
- Prompt injection: por qué tu agente de IA no es seguro (y cómo arreglarlo)
- El problema de los tokens en la IA que programa (y cómo lo resuelve Codebase Memory MCP)